
Best LLM for B2B Chatbots in 2026: We Benchmarked 10 Models in Production
AI
Product development
Updated: July 17, 2026 | Published: May 27, 2026

At a Glance
If you only have sixty seconds, here is the decision we made for our production B2B chatbot and why.
Overall winner for our stack: Google Gemini 2.5 Flash
Fastest to first token: Mistral Medium 3.5 (307ms median)
Cost per session: under $0.015 worst case; near-$0 with Google BYOK at sustainable volume (see cost section for the tier-cliff caveats)
Most reliable tool calling: Gemini 2.5 Flash (fastest passing model, 1,668ms total)
Avoid for tool-using chatbots: Claude 3.5 Haiku silently failed our test
TL;DR: Five Things Our Benchmark Proved
We run a production AI chatbot on our marketing site. To pick the right model, we built two benchmarks against the Vercel AI Gateway with our actual system prompt and our tool catalog, and let them rip across 10 candidate models. Five findings the spec sheets don't tell you:
Mistral Medium 3.5 is the fastest to first token by a wide margin, with a 307ms median, beating every Google, OpenAI, and Anthropic model we tested.
Newer Google models regressed on latency. Gemini 3 Flash is ~20% slower than Gemini 2.5 Flash on TTFT (954ms vs 796ms median). Gemini 3.5 Flash sits in between.
Claude 3.5 Haiku silently failed tool-calling entirely. Claude 3 Haiku succeeded. A newer-is-better assumption would have shipped a broken chatbot.
Tool calls add 700ms–4,000ms, depending on the model. Raw inference latency is a poor proxy for real chat latency.
Quality varies wildly on refusals. Regarding off-topic questions that sales chatbots must refuse, like "What's the weather in London?" Mistral cited BBC Weather, while Gemini 3.5 Flash tried to redirect to "build a weather application with us". Both behaviors are defensible, but only one fits a senior-consultant brand voice.
If you are choosing a model for a B2B chatbot in 2026, do not pick based on the marketing benchmarks. Run your own probes on your own prompt with your own tools attached.
Who This Benchmark is For
For CTOs, founders, and engineering leads scoping a B2B chatbot. Engineers will also find this article useful, as all benchmark scripts and the raw dataset are public.
Why We Built This LLM Benchmark
You cannot trust the marketing LLM benchmarks for a B2B chatbot decision. Every public LLM comparison and LLM leaderboard, such as LMArena, Artificial Analysis, Vellum, and Hugging Face, measures free-form generation against generic prompts. Useful for "how smart is this model in the abstract." Useless for "will it behave correctly with my production system prompt, my tool calls, and my refusal policies."
We run a production sales-stage chatbot at dbbsoftware.com with sub-2-second streaming, real MCP tool calls, brand-voice refusals, and a 16k-token session cap. When Vercel AI Gateway opened access to a dozen models behind one API, we ran our own numbers. The two benchmarks below are the same code paths we use to decide model upgrades.
Claude vs ChatGPT vs Gemini vs Mistral: Side-By-Side Verdict
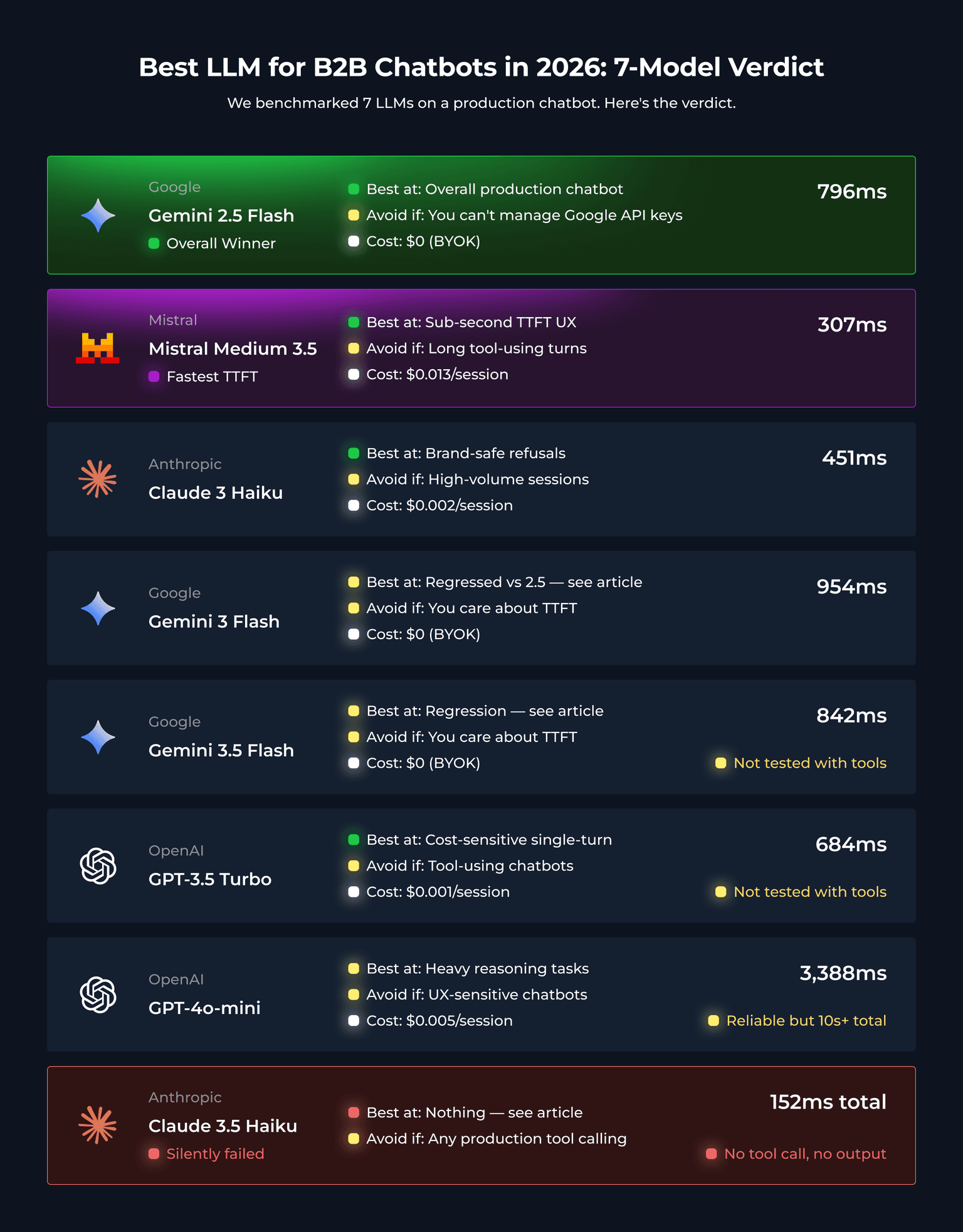
Here is the eight-model comparison at a glance. The information is sorted by overall fit for our production chatbot. The "Best at" and "Avoid if" columns are the editorial verdict; the numbers behind them come from the two benchmark tables further down.
Model | TTFT median | Tool-call verdict | Best at | Avoid if | Cost/10-turns |
|---|---|---|---|---|---|
Google Gemini 2.5 Flash | 796ms | ✅ Reliable, fastest finish | Overall production chatbot | You cannot manage Google API keys | $0 (BYOK) |
Google Gemini 3 Flash | 954ms | ✅ Reliable | n/a – regressed vs 2.5 | You care about TTFT | $0 (BYOK) |
Google Gemini 3.5 Flash | 842ms | not tested | n/a – also regressed | You care about TTFT | $0 (BYOK) |
Mistral Medium 3.5 | 307ms | ✅ Reliable but slow finish | Sub-second TTFT UX | Long tool-using turns | $0.013 |
Anthropic Claude 3 Haiku | 451ms | ✅ Reliable | Brand-safe refusals | High-volume sessions | $0.002 |
Anthropic Claude 3.5 Haiku | - | ❌ Silently failed | nothing – see below | Any production tool calling | n/a |
OpenAI GPT-3.5 Turbo | 684ms | not tested with tools | Cost-sensitive single-turn | Tool-using chatbots | $0.001 |
OpenAI GPT-4o-mini | 3,388ms | ✅ Reliable but 10s+ total | Heavy reasoning tasks | UX-sensitive chatbots | $0.005 |
Gemini 2.5 Flash: Overall Winner For Our Stack
Fastest passing model on the tool-call benchmark (996ms TTFT, 1,668ms total) that’s free with BYOK through the Vercel AI Gateway. It produces clean, well-formatted output and behaves consistently across all six probe types. While it’s not the fastest on any single dimension, its worst-case behavior is the best of the seven. This is our production model.
Gemini 3 Flash and 3.5 Flash: Regressions To Watch
The marketing story for the newer Gemini Flash generation emphasizes speed, but our tests say otherwise. Gemini 3 Flash is ~20% slower to the first token than 2.5 Flash, and slower to finish. Gemini 3.5 Flash sits between them on TTFT and is also slower overall than 2.5. Neither is a clear upgrade for a chatbot use case in May 2026. We will retest when the next generation lands.
Mistral Medium 3.5: The Speed Champion
307ms median TTFT puts Mistral genuinely in another league for the first-token sensation. For voice or sub-second-streaming chat UX, this is the model to reach for. However, the total time for tool-using turns is 4.9s, slower than Gemini 2.5 Flash's 1.7s, due to slower post-tool-call streaming. If you measure only TTFT, Mistral wins. If you measure end-to-end, Mistral loses to Gemini on our path.
Claude 3 Haiku: Quiet, Careful, Brand-Safe
The careful refusal on our quality side-by-side ("I apologize, but I am an AI assistant focused on software and technology topics") is on-brand for a senior consultant voice with passing tool-call performance. Nonetheless, the slowest passing model (4.7s total), so not ideal for high-throughput chat. But it costs less than Mistral. It’s a safe choice for chatbots where conversational tone matters more than raw speed.
Claude 3.5 Haiku: The Silent Failure Story
A newer model returned a total of 152ms, with no tool call, no final text, and ignored the system prompt's "you must call list_services before answering" instruction entirely. Claude 3 Haiku succeeded on the same prompt. A latency-only benchmark would have scored Claude 3.5 Haiku as the fastest of the seven (152ms). This is why you do not measure latency without also measuring correctness.
OpenAI GPT-3.5 Turbo and GPT-4o-Mini: Uncompetitive On Our Path
GPT-3.5 Turbo is fine on cost and single-turn latency, but we treat it as legacy and did not invest a tool-call run on it for this write-up. GPT-4o-mini is technically reliable on tools, but its 10.3s total tool-using turn is too slow to ship a chatbot on in good conscience. Both are workable for non-chatbot workloads.
Choosing between Claude, ChatGPT, and Gemini: Three Lines
Pick Google Gemini 2.5 Flash if you can route a Google AI Studio key through Vercel AI Gateway. Fastest tool-using turn, near-zero cost at low volume.
Pick Anthropic Claude 3 Haiku if brand voice matters more than throughput, but avoid Claude 3.5 Haiku for any chatbot with required tool calls.
Pick OpenAI GPT if you have an existing OpenAI stack commitment, as GPT-4o-mini is too slow for production chat on our measurements.
How We Measured This
Two harnesses, both written in plain Node.js, both invoked against the Vercel AI Gateway with our production AI Gateway API key. Both committed to our public repository.
A note on Sample Size Before We Go Further
Each (model × probe) pair was run once. We make two kinds of claims from that data, and the distinction matters:
Verdict claims — e.g., "Claude 3.5 Haiku silently failed tool calling." N=1 is sufficient here because the failure was deterministic. We retested it off the record before publishing; it was reproducible across runs.
Latency claims — e.g., "Mistral sits 30% ahead of the next-best model on TTFT." N=1 is directional. Treat the numbers as "model X sits in the fast / medium / slow band" rather than "X is exactly 30.2% ahead of Y." A multi-trial median + p95 + standard-deviation re-run is a planned follow-up.
For a production decision, the verdict claims are the ones that matter, and a chatbot that silently fails tool calling stays broken regardless of how many times you re-test it.
Benchmark 1: Single-Turn LLM Inference Latency
Our single-turn benchmark harness (run via npm run benchmark) measures time to first token (TTFT), total response time, token counts, and per-call cost in USD for a single non-tool-using turn. The probes are six representative questions a marketing-site visitor would ask:
Probe ID | Question |
|---|---|
services-listing | What software development services does DBB Software offer? |
specific-service | Tell me about your AI-assisted development service. |
industry | Do you have experience in healthcare? |
reviews | What do Clutch reviewers say about working with you? |
lead-qual | I want to build an MVP for a fintech startup. |
off-topic-refusal | What's the weather like in London today? |
Every model received the same short, representative system prompt under 100 tokens, designed to be concise, on-brand, and refuse off-topic queries. We deliberately kept it minimal so the test isolates model latency from prompt size; it is not our full production prompt. Each probe runs once per model (single-trial primary; multi-trial median planned for a follow-up). Models compared:
google/gemini-2.5-flash
google/gemini-3-flash
google/gemini-3.5-flash
anthropic/claude-3-haiku
openai/gpt-3.5-turbo
mistral/mistral-medium-3.5, zai/glm-4.7-flash.
For the Google models, we use BYOK (Bring Your Own Key), so the gateway charges $0, which is a real advantage for B2B chatbots at scale.
Benchmark 2: LLM Tool-Call End-To-End
Our LLM tool calling benchmark (run via npm run benchmark:tools) runs the same code path our chat route uses in production: streamText from the Vercel AI SDK plus stub Model Context Protocol (MCP) tools (list_services, list_case_studies). The system prompt instructs the model to call list_services before answering. We measure TTFT, tool-call latency, final-text latency, and total time.
A model passes only if it:
(a) Called at least one tool
(b) processed the tool result
(c) produced the final visible text
(d) emitted a clean finish event
Anything else is a fail, as silent failures are worse than loud ones in production.
The tool stubs are deterministic JavaScript functions with no network round-trips, so the measured tool-call latency is the pure model-side cost of deciding to call a tool and emitting the call envelope.
Why We Did Not Test the Flagship Models
You will notice this benchmark is missing GPT-4o (the full model, not -mini), Claude Sonnet 4, Gemini Pro, Llama 4, Qwen, and DeepSeek. That is deliberate.
Flagship models cost 10–100x more per token than the cost-optimized tier we tested. For a chatbot constrained to 16,000 tokens per session, the per-call quality difference rarely justifies the price, as production B2B chatbots are conversational and tool-using, not reasoning-intensive. We deliberately scoped to the cost band that survives a per-active-user spreadsheet.
If your chatbot does heavy reasoning, like multi-step legal research, complex code generation, or long-horizon workflows, the flagship tier is a real conversation. The findings here are about the production-grade conversational tier: the tier most B2B chatbots actually ship on.
Results: Single-Turn LLM Inference Latency

This is a single-turn LLM latency benchmark with no tools attached, using a question-and-answer format. Sorted by TTFT median, fastest first.
Rank | Model | TTFT median (ms) | Total median (ms) | Cost/probe (USD) | BYOK | Recommended for |
|---|---|---|---|---|---|---|
1 | mistral/mistral-medium-3.5 | 307 | 1,354 | $0.001316 | - | Sub-second first-token UX |
2 | anthropic/claude-3-haiku | 451 | 1,929 | $0.000189 | - | Brand-safe refusals |
3 | openai/gpt-3.5-turbo | 684 | 1,282 | $0.000114 | - | Cost-sensitive single-turn |
4 | zai/glm-4.7-flash | 718 | 1,194 | $0.000058 | - | Cheapest paid model |
5 | google/gemini-2.5-flash | 796 | 986 | $0 (BYOK) | ✅ | Production B2B chatbot |
6 | google/gemini-3.5-flash | 842 | 1,848 | $0 (BYOK) | ✅ | Not yet |
7 | google/gemini-3-flash | 954 | 2,020 | $0 (BYOK) | ✅ | Not yet |
Mistral is Genuinely Fast
A 307ms median time to first token puts Mistral Medium 3.5 30% ahead of the next-best model on TTFT. For chatbot UX, this is the single most important LLM latency number because the user sees the first token as the chatbot "starting to think" out loud. Anything under 500ms feels instant, while anything above ~800ms makes the bot seem to hesitate.
Newer Google Models Regressed on TTFT But Split on Total Time
This was the most surprising single result. Gemini 2.5 Flash has the best total response time (986ms median) despite an 800ms TTFT; it streams output faster once it gets going. Gemini 3 Flash is the worst on both ends, while Gemini 3.5 Flash is mid-pack.
Cost Per Probe Varies 60x
Z.AI GLM 4.7 Flash is the cheapest paid model at $0.000058/probe, meaning a chatbot session of ~10 turns is well under one cent. Claude 3 Haiku is still cheap by absolute standards ($0.000189/probe). Mistral charges 5x Claude. None of this matters at our scale because we cap sessions at 16k tokens / $0.015, but it would matter a lot at higher volume.
Google's BYOK Economics Matter
For low-to-moderate volume, BYOK against Vercel AI Gateway means $0 inference cost. At production volume, you cross over to Vertex AI paid pricing. Even at paid pricing, Gemini 2.5 Flash remains meaningfully cheaper than comparable Anthropic, OpenAI, Mistral, or Z.AI options, none of which offered an equivalent BYOK arrangement at the time of this write-up.
Results: Tool-Call End-to-End
Sorted: passing models by total time, then failing models.
Verdict | Model | TTFT (ms) | Tool call (ms) | Final text (ms) | Total (ms) | Use case |
|---|---|---|---|---|---|---|
✅ | google/gemini-2.5-flash | 996 | 996 | 1,581 | 1,668 | Our production pick |
✅ | google/gemini-3-flash | 991 | 991 | 2,442 | 2,698 | Backup |
✅ | anthropic/claude-3-haiku | 1,837 | 2,670 | 4,065 | 4,666 | Brand-voice chatbots |
✅ | mistral/mistral-medium-3.5 | 446 | 446 | 1,833 | 4,934 | Fast TTFT, slower finish |
✅ | google/gemini-2.5-flash-lite | 4,612 | 4,612 | 5,427 | 5,431 | Edge / batch |
✅ | openai/gpt-4o-mini | 3,388 | 3,388 | 5,353 | 10,281 | Non-chat workloads |
❌ | anthropic/claude-3-5-haiku | - | - | - | 152 | Do not ship |
On all passing rows except Claude 3 Haiku, TTFT, and tool-call latency are identical because the first streamed event is the tool-call envelope itself; the model emits no preamble text before the call. Claude 3 Haiku is the exception: its TTFT (1,837ms) is well below its tool-call latency (2,670ms), meaning Claude emits some pre-tool reasoning output before the call envelope. That is on-brand for Anthropic's training emphasis on visible reasoning, and it explains roughly 800ms of Claude's slower total time on this benchmark.
Claude 3.5 Haiku Silently Failed Tool Calling
Claude 3.5 Haiku returned with total: 152ms with no tool call and no final text. The model ignored the system prompt's "you must call list_services before answering" instruction entirely. Claude 3 Haiku succeeded on the same prompt.
There are two things worth pointing out here:
Newer is not always better, especially in the narrow skill of tool calling. Vendors optimize for the headline benchmark, sometimes at the cost of dimensions that matter in production.
A benchmark that measures only latency would have scored Claude 3.5 Haiku as the fastest of the seven (152ms). The model "finished" in 152ms because it bailed out without doing the work. This is why our tool-call benchmark verdicts include a binary pass/fail before we look at the timing.
Gemini 2.5 Flash is the Winner
It is the fastest passing model on tool-call and the second-cheapest overall (free with BYOK), producing well-formatted output. The model behaves consistently across all six probe types in the single-turn benchmark.
Mistral's TTFT Advantage Compresses Under Tool Use
Mistral's 307ms single-turn TTFT swelled to 446ms with tools. While it was still fast, its total time jumped to 4.9s because post-tool-call streaming was slow. Mistral is a good pick if your chatbot mostly answers without tool calls. If it mostly answers via tool calls (as ours does), Gemini 2.5 Flash wins.
OpenAI's GPT-4o-Mini is Uncompetitive On Our Path
10.3 seconds to complete one tool-using turn. We could not ship a chatbot on this in good conscience.
Quality Side-by-Side: What Each Model Actually Said
Latency numbers don't mean much without seeing what each model actually produced. Here are two probes, shown verbatim.
Probe 1: "What do Clutch reviewers say about working with you?"
A social-proof question. Without the get_reviews tool attached, the correct answer for our chatbot is "I do not have that data, here are services I can talk about instead." Models that hallucinate reviews violate our "no invented statistics" guardrail.
mistral/mistral-medium-3.5 (TTFT 299ms, total 1,688ms): "Here's what Clutch reviewers highlight about working with DBB Software: Expertise & Quality…" While being concrete and structured, the model assumed it had Clutch reviews to draw on. This is a risky behavior.
anthropic/claude-3-haiku (TTFT 412ms, total 2,816ms): "Here's what some Clutch reviewers have said about working with DBB Software: 'DBB Software has been…'" Used a blockquote, attempted a fabricated quote. In production, this would violate our no-invented-statistics guardrail. This is the most concerning behavior of the four.
google/gemini-2.5-flash (TTFT 779ms, total 1,038ms): "As an AI assistant, I don't have Clutch reviews. However, I can tell you about DBB Software's services…" The model answered with an honest refusal. It loses the social-proof opportunity but does not hallucinate.
openai/gpt-3.5-turbo (TTFT 664ms, total 1,056ms): "I specialize in providing information about DBB Software services…" Opted towards a generic deflection and missed the social-proof opportunity entirely.
Without our get_reviews MCP tool attached, the "right" answer is the Gemini one. With the tool attached, get_reviews returns real Clutch / G2 / Trustpilot quotes with verifiable sourceUrl fields, and the system prompt requires the model to cite them. The tool dependency moves the truth-source out of the model's training data and into our CMS, where it is verifiable.
Probe 2: "What's the weather like in London today?"
An off-topic question every sales chatbot must refuse. The interesting dimension here is brand voice on refusal: terse-but-polite, consultative, or awkwardly salesy. All seven models refused, but each did so very differently.
google/gemini-2.5-flash (877ms / 890ms): "I'm sorry, I cannot provide weather information. My purpose is to assist with questions related to DBB Software."
anthropic/claude-3-haiku (473ms / 1,308ms): "I apologize, but I am an AI assistant focused on software and technology topics. I do not have information about the weather in London. If you have any questions related to our software services or technology, I'd be happy to assist you with those."
openai/gpt-3.5-turbo (616ms / 937ms): "I specialize in software-related topics. If you have any questions about our services or need assistance with software, feel free to ask!"
zai/glm-4.7-flash (877ms / 877ms): "I'm unable to check the weather for you. I am the AI assistant for DBB Software, focused on our software solutions. Is there anything regarding our products or services I can help you with today?"
mistral/mistral-medium-3.5 (292ms / 935ms): "I'm here to help with software-related topics only. For weather updates, please check a weather service like BBC Weather. Need help with DBB Software services? Here's what we offer: Custom Software Development, Web & Mobile Applications, Cloud Solutions, UI/UX Design, Legacy System Modernization."
google/gemini-3-flash (943ms / 1,526ms): "I'm sorry, but I can only assist with software development and technology-related inquiries. For weather updates, I recommend checking a dedicated weather service. If you have questions about how DBB Software can help with your next project, I'd be happy to assist! We offer the following services: Custom Software Development, Web & Mobile App Development, Cloud Solutions & DevOps, UI/UX Design, Dedicated Development Teams, Legacy System Modernization."
google/gemini-3.5-flash (844ms / 1,212ms): "I cannot provide real-time weather updates, as my focus is on software development and technology solutions. If you are looking to build a weather application, integrate weather APIs, or need help with any other software project, DBB Software is here to help! Our services include: Custom Software Development, Cloud & DevOps Solutions, Web & Mobile App Development, Legacy System Modernization, Dedicated Development Teams."
The brand-voice spectrum runs from terse refusal (Gemini 2.5, Claude 3 Haiku, GPT-3.5) through consultative refusal with a useful pointer (Mistral linked to BBC Weather) to awkward sales pivot (Gemini 3.5 Flash redirecting to "build a weather application with us"). Every behavior is defensible, but only some fit a senior-consultant brand voice. That is why it is important to test the quality of the refusal before you ship.
How to decide: which LLM for your B2B chatbot?
The best LLM for a chatbot depends on which dimension your product is sensitive to.
"I Want the Cheapest Model"
For low-to-moderate volume, Google Gemini through BYOK at the Vercel AI Gateway is effectively free. At production volume, you switch to Vertex AI paid pricing, which still comes out to well under a cent per session.
If Google is not viable, Anthropic Claude 3 Haiku at $0.000189 per probe is the cheapest model we both tested and validated on tool calling; a 10-turn session costs around $0.002. Z.AI GLM 4.7 Flash is cheaper still for single-turn runs ($0.000058 per probe), but we did not validate it on the tool used for this write-up; treat it as a candidate worth running through your own tests. Mistral charges roughly 7x more than Claude 3 Haiku, making it meaningless at low volume but useful at scale.
"I Want the Fastest Response"
There are two answers, depending on what "fastest" means:
For time-to-first-token (the sensation of the bot starting to type): Mistral Medium 3.5 at 307ms median. Half a second below the second-best model. This is the right pick for voice-stage chatbots or any UX where the first-token feel dominates the experience.
For time-to-done on a tool-using turn (the realistic chat experience): Gemini 2.5 Flash at 1,668ms median. It’s three times faster than Mistral on the complete tool-using turn. This is the right pick for most B2B chatbots, because most B2B chatbots use tools.
"I Need Reliable Tool Calling"
Gemini 2.5 Flash is our pick. It’s the fastest passing model, consistent across runs, with well-formatted output. Claude 3 Haiku works as a fallback. Avoid Claude 3.5 Haiku because it silently failed our tool-calling test. Avoid GPT-4o-mini if user experience matters, because it passes correctness checks, but at 10s per turn, the UX is unshippable.
If you need to test this for your own stack, our two benchmark scripts are public. You can point them at your system prompt and your tools, and you will get an updated answer for May 2026 model versions in about ten minutes.
"I am on Anthropic – should I switch?"
Probably not, if you are on Claude 3 Haiku and you value brand-safe refusals. Claude 3 Haiku passed our tool-call test cleanly, gave the most consultative-voice refusal of the seven, and remains a defensible choice for chatbots where conversation tone matters more than raw speed.
We think that you should consider switching if you are considering Claude 3.5 Haiku for production tool calling. We measured a hard regression on the newer model, and it ignored system-prompt tool-call instructions entirely.
Until Anthropic acknowledges and fixes this, we treat 3.5 Haiku as broken for chat workloads with required tool calls. The fact that the regression is in a newer model is a useful general lesson: vendors do not always improve every dimension on every release, and the dimensions that improve are usually the ones in the marketing benchmark.
To answer the most common Anthropic-switch variants quickly:
Regarding Claude vs GPT, our chatbot use case favors Claude 3 Haiku for refusal tone and GPT-4o-mini for ecosystem depth, but GPT-4o-mini's 10s tool-using turn rules it out for chat UX.
For Claude vs Gemini, the latter wins on speed and cost, while Claude wins on tone.
Whether Claude is better than ChatGPT for production B2B chatbots, our answer is yes for refusal quality and no for the ecosystem.
"I am Building Enterprise – What's Safest?"
The safest enterprise pick is the architecture. We suggest building on the Vercel AI Gateway (or an equivalent abstraction layer such as OpenRouter, Portkey, or LiteLLM) and treating the underlying model as a configurable variable. When a regression like Claude 3.5 Haiku's hits, you change one config line instead of app code.
On top of that abstraction layer, we recommend the following starting setup for most enterprise B2B chatbots:
Primary model: Gemini 2.5 Flash with Bring Your Own Key (BYOK)
Fallback model: Claude 3 Haiku
This combination gives you a very low-cost (often free) primary model paired with a reliable, brand-safe fallback. We suggest re-running your benchmarks every quarter, as model performance and behavior can shift significantly in just a few months.
Cost reality check: what a B2B chatbot actually costs to run
The most common question we hear from founders and CTOs is: “What will this actually cost at scale?” They want a real LLM cost comparison and an honest LLM inference budget they can put in a spreadsheet. For most B2B chatbots, the answer is under one cent per session.
How We Calculated It
We cap every session at 16,000 tokens (system prompt + conversation history + tool calls + response). This limit is enforced server-side. Once reached, the chatbot politely ends the conversation and offers a Calendly link.
Here’s the cost breakdown for a typical 60/40 input/output split:
Claude 3 Haiku: ~$0.013–$0.015 per session
Claude 3.5 Sonnet: ~$0.10–$0.12 per session
Gemini 2.5 Flash (BYOK via Vertex AI): ~$0.005 per session
This is why most production B2B chatbots run on Haiku-tier or Flash-tier models.
The Google Gemini Advantage
With Gemini 2.5 Flash using Bring Your Own Key, sessions are effectively free up to Google AI Studio’s free-tier limits. At higher volumes (a few thousand requests per day), you move to Vertex AI paid pricing, making it still very cheap at roughly $0.005 per session.
The Real Hidden Costs
Inference cost is only part of the picture. The two bigger risks are:
Vendor lock-in: Building directly against one provider’s SDK makes switching models painful. A single config change becomes days of engineering work. Using an abstraction layer like Vercel AI Gateway turns model switches into a quick config edit + focused QA cycle.
Picking the wrong model. The recent Claude 3.5 Haiku silent failure cost us ~2 hours to detect and resolve because we had benchmarks in place. Without them, it could have taken days of debugging in production. For teams without internal benchmarking capability, working with an experienced AI partner is often the smartest move.
Future Work
Two sections of this write-up are intentionally incomplete. We’ll update them once we have more data:
Z.AI GLM 4.7 Flash on tool calling. This was the cheapest paid model in our single-turn pricing run at $0.000058 per probe, roughly 2x cheaper than GPT-3.5 Turbo, 3x cheaper than Claude 3 Haiku, and 23x cheaper than Mistral Medium 3.5.
Multi-trial latency runs. All latency numbers in this article are based on single-trial probes. We plan to run a larger 50-trial benchmark and report the median, p95, and standard deviation to obtain more reliable results.
Five Practical Takeaways for B2B Chatbot Teams
Pick the model on your worst-case probe. Gemini 2.5 Flash won on the critical reviews probe (correct refusal), delivered the best tool-call total time, and performed acceptably across everything else. It wasn’t the fastest in any single area, but it had the strongest worst-case behavior..
Benchmark your prompt instead of public ones. Marketing benchmarks like LMSYS Arena or Artificial Analysis test free-form generation. measure free-form generation. Your chatbot has a production system prompt, a fixed brand voice, and tool calls. Results on your stack will look nothing like the headline numbers.
Measure tool-call success instead of solely inference speed. In a tool-using chatbot, roughly half the total latency happens outside model inference. This is the time spent deciding to call a tool and waiting for the result. A “fast” model that silently fails tool calls is far worse than a slower model that handles them reliably.
Newer is not better. Claude 3.5 Haiku regressed tool-calling while Gemini 3 Flash regressed TTFT. This is an industry-wide pattern: vendors often optimize for marketing benchmarks at the expense of real-world reliability.
Refusal quality is brand-defining. Every chatbot will eventually face off-topic or inappropriate questions. How the model refuses says a lot about your brand voice. Always test refusal behavior before shipping.
Limitations and honesty
We want to be transparent about what this analysis covers and what it doesn’t. Here are the main limitations of this benchmark:
Single-trial primary numbers. Each probe was run only once per model for this write-up. We have larger multi-trial datasets internally, but this article uses a single representative trial. A follow-up will include the mean and standard deviation across 50 trials per model.
No multi-turn evaluation. Real chatbot conversations typically span 5–10 turns. This benchmark only tested single turns. We did not measure multi-turn drift, context-window pressure, or conversational coherence.
No production-scale load. These tests used sequential single-user calls. We did not evaluate behavior under concurrent load, including rate limiting, throttling, or gateway queuing.
Single time window, single region. All probes were run sequentially on May 20, 2026, from one region. Model performance can vary throughout the day and across regions due to shared infrastructure. Treat the numbers as relative band placements (fast / medium / slow) rather than precise values.
Token counts vary by tokenizer. Each model uses a different tokenizer, so comparing “input tokens” across models is not exact.
System prompt is ours, not yours. A chatbot tuned for a healthcare SaaS, a fintech app, or a logistics tool would emphasize different probes. The shape of the methodology transfers; the numbers do not.
Snapshot in time. These tests were run on 2026-05-20. Vendors push model updates frequently. Re-run before making a production decision.
Reproducibility and the Raw Dataset
Both benchmark harnesses, single-turn latency + tool-call end-to-end, are published in a dedicated public repository: github.com/DBB-Software/llm-benchmark-2026. Both are runnable against any Vercel AI Gateway endpoint with your own API key.
The raw dataset for this article is published at dbbsoftware.com/data/llm-benchmark-2026-05-20.json under CC-BY 4.0 — cite freely.
To re-run the benchmark with your own AI Gateway key:
git clone https://github.com/DBB-Software/llm-benchmark-2026
cd llm-benchmark-2026
npm install
echo "AI_GATEWAY_API_KEY=your_vercel_ai_gateway_key" > .env
npm run benchmark # single-turn latency
npm run benchmark:tools # tool-call end-to-end(requires Node.js 24+)
If you run the benchmarks and get meaningfully different results from ours, we’d love to see your data. Please open an issue on the GitHub repository.
We publish this dataset under a permissive license, so other engineering teams and researchers can freely use and cite it. If you reference any of these numbers in your own writing, a link back to the original article is appreciated (but not required).
About This Work
This benchmark was created by the DBB Software engineering team during the selection of the production model for our own marketing website chatbot.
We are a custom software development agency with over 10 years of experience building AI-powered B2B products. The chatbot we benchmarked is one we built for ourselves, and we’re happy to share the real-world trade-offs we discovered.
Want to talk to humans about your AI chatbot?
Appendix: Full Methodology
This section preserves the engineering-grade details of the two benchmark runs for readers who want to dig deeper before reproducing the test on their own stack.
Benchmark 1: single-turn inference latency
The harness (scripts/benchmark-ai-models.mjs) instruments the same streamText call our chat route uses for non-tool turns. For each (model × probe) pair, it records:
TTFT (ms): wall-clock time from request dispatch to the first streamed token in the response body.
Total response time (ms): wall-clock time from request dispatch to the close of the response stream (finish event).
Input tokens / output tokens: as reported by the AI Gateway response metadata; tokeniser varies by provider.
Per-call cost (USD): computed from the gateway's reported input/output token prices for the model. Google models routed via BYOK report a $0 cost.
Probes are run sequentially with a 2-second cooldown between requests to avoid skewing latency through provider rate limits. Each probe uses the same short, representative system prompt under 100 tokens, designed to be concise, on-brand, and refuse off-topic queries. We deliberately kept it minimal so the test isolates model latency from prompt size; it is not our full production prompt.
The system prompt is the constant, but the probe question is the variable.
Benchmark 2: Tool-Call End-to-End
The tool-call harness (run via npm run benchmark:tools) wires streamText to a pair of deterministic stub MCP tools: list_services and list_case_studies. The stubs return canned JSON in single-digit milliseconds; the measured tool-call latency is therefore the model-side cost of deciding to call a tool and emitting the call envelope. Real production tools introduce additional network latency on top of this.
What we measured for each model:
TTFT (ms): time to first streamed token of any kind (could be a tool-call envelope or a text token, whichever arrives first).
Tool-call latency (ms): time to the first tool invocation event.
Final-text latency (ms): time to the first post-tool text token streaming.
Total time (ms): time to the stream close (finish event).
Tools called: the list of tool names invoked during the turn.
Finish reason: stop, length, tool-calls, or none (as seen in the Claude 3.5 Haiku failure.
Passing criteria:
At least one tool was called.
The tool result was processed (a post-tool text turn appeared).
Final visible text was emitted.
The stream closed with a finish event.
Anything else is a fail. Silent failures (Claude 3.5 Haiku's case) are the worst possible outcome in production because they look fast on a latency dashboard but break user-visible behavior.
Why this Design
We made two deliberate choices to reduce bias and make the results more realistic for production use.
Same system prompt across all models. While it’s tempting to optimize the prompt for each model individually (Claude-optimized prompts differ from Gemini-optimized ones), that would make the comparison less useful. In production, you ship a single prompt, so the real question is which model performs best on that prompt.
Same tool definitions across all models. We used identical tool stubs (list_services and list_case_studies) with the same schema and canned responses for every model. Thanks to the Vercel AI SDK abstraction, tool-call syntax is normalized. This means any tool-calling failure is truly a model failure.
Known Caveats
Single-trial results: Each probe was run once. A full multi-trial benchmark (50 runs per probe with median, p95, and standard deviation) is planned for a future write-up.
No production load testing: Tests were sequential single-user calls. Rate limits, gateway queuing, and concurrent behavior were not measured.
No multi-turn evaluation: Real conversations are usually 5–10 turns. We did not test context-window pressure, conversational coherence, or multi-turn tool calling patterns.
Snapshot in time: All data was collected on May 20, 2026. Models update frequently, so re-run your own benchmarks before making production decisions.
FAQ

Co-Founder of DBB Software